RoundSparrow
- RoundSparrow@lemmy.ml
- Banned
“Finnegans Wake is the greatest guidebook to media study ever fashioned by man.” - Marshall McLuhan, Newsweek Magazine, page 56, February 28, 1966.
I have never done LSD or any other illegal drugs, but I have read FInnegans Wake: www.LazyWake.com
Lemmy tester, “RocketDerp” is my username on GitHub
- 4 Posts
- 9 Comments
- RoundSparrow@lemmy.mlBannedOPto
 3·3 years ago
3·3 years agoBetter file a bug about that
Bug has been open for weeks. Doesn’t seem to be a priority to undo the added HTML sanitation problems.
The code I pasted here on Lemmy is also on GitHub comment without being munged: https://github.com/LemmyNet/lemmy/pull/3865#issuecomment-1683324467
It’s still mostly like the original function it is copied from, just some of the logic has been successfully stripped out. But it’s probably worth looking at the bigger picture of just how much of the Rust conditional logic goes into building this SQL statement.
- RoundSparrow@lemmy.mlBannedOPto
 1·3 years ago
1·3 years agoThank you
- RoundSparrow@lemmy.mlBannedOPto
Good results with this approach. I hadn’t considered the RANK OVER PARTITION BY criteria_a values and it works like a champ. It moves the ORDER BY into the realm of focus (criteria_a) and performance seems decent enough… and it isn’t difficult to read the short statement.
SELECT COUNT(ranked_recency.*) AS post_row_count FROM ( SELECT id, post_id, community_id, published, rank() OVER ( PARTITION BY community_id ORDER BY published DESC, id DESC ) FROM post_aggregates) ranked_recency WHERE rank <= 1000 ;Gives me the expected results over the 5+ million test rows I ran it against.
If you could elaborate on your idea of TOP, please do. I’m hoping there might be a way to wall the LIMIT 1000 into the inner query and not have the outer query need to WHERE filter rank on so many results?
- RoundSparrow@lemmy.mlBannedOPto
Ok, I’m doing some reading: https://medium.com/@amulya349/how-to-select-top-n-rows-from-each-category-in-postgresql-39e3cfebb020
- RoundSparrow@lemmy.mlBannedOPto
I found the total table update wasn’t as bad performing as I thought and the API gateway was timing out. I’m still generating larger amounts of test data to see how it performs in edge worst-case situations.
- RoundSparrow@lemmy.mlBannedOPto
I agree there is potential to reuse the child_count from child/grandchild rows. But there has to be some sense to the order they are updated in so that the deepest child gets count updated first?
- RoundSparrow@lemmy.mlBannedOPto
So it turns out that the query was finishing within minutes and the API gateway was timing out. Too many Lemmy SQL statements in my head. On a test system update of all the comment second run just took under 17 seconds for 313617 rows that has some decent reply depth, so it isn’t as bad as I thought.
- RoundSparrow@lemmy.mlBannedOPto
given it traverses all the comment X comment space every time a comment is added.
The second query I shared is only referenced for maintenance rebuild. The routine update of count does target only the tree that the reply is to:
select c.id, c.path, count(c2.id) as child_count from comment c join comment c2 on c2.path <@ c.path and c2.path != c.path and c.path <@ '0.1' group by c.idI found a particularly complex tree with 300 comments. In production database (with generated test data added for this particular comment tree), it is taking .371 seconds every time a new comment is added, here is the result of the SELECT pulled out without the UPDATE:
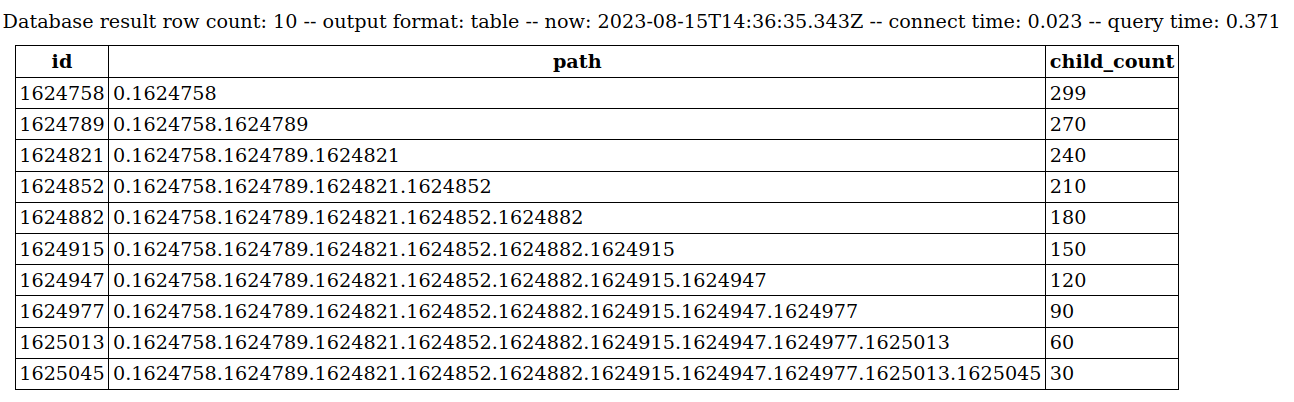
Obviously with the UPDATE it will take longer than .371 seconds to execute.
I have, weeks ago.
I did share a link to GitHub, is that not good enough or something? Here is a screen shot for you.