

13·
2 years ago
Sufficiently advanced prompts are indistinguishable from prayer
Hi, I’m Eric and I work at a big chip company making chips and such! I do math for a job, but it’s cold hard stochastic optimization that makes people who know names like Tychonoff and Sylow weep.
My pfp is Hank Azaria in Heat, but you already knew that.
Sufficiently advanced prompts are indistinguishable from prayer
Is it time for EAs to start worrying about Neopets welfare?
If you really wanna just throw some fucking spaghetti at the wall, YOU CAN DO THAT WITHOUT AI.
i have found I get .000000000006% less hallucination rate by throwing alphabet soup at the wall instead of spaghett, my preprint is on arXiV
THIS IS NOT A DRILL. I HAVE EVIDENCE YANN IS ENGAGING IN ACASUAL TRADE WITH THE ROBO GOD.

Found in the wilds^
Giganto brain AI safety ‘scientist’
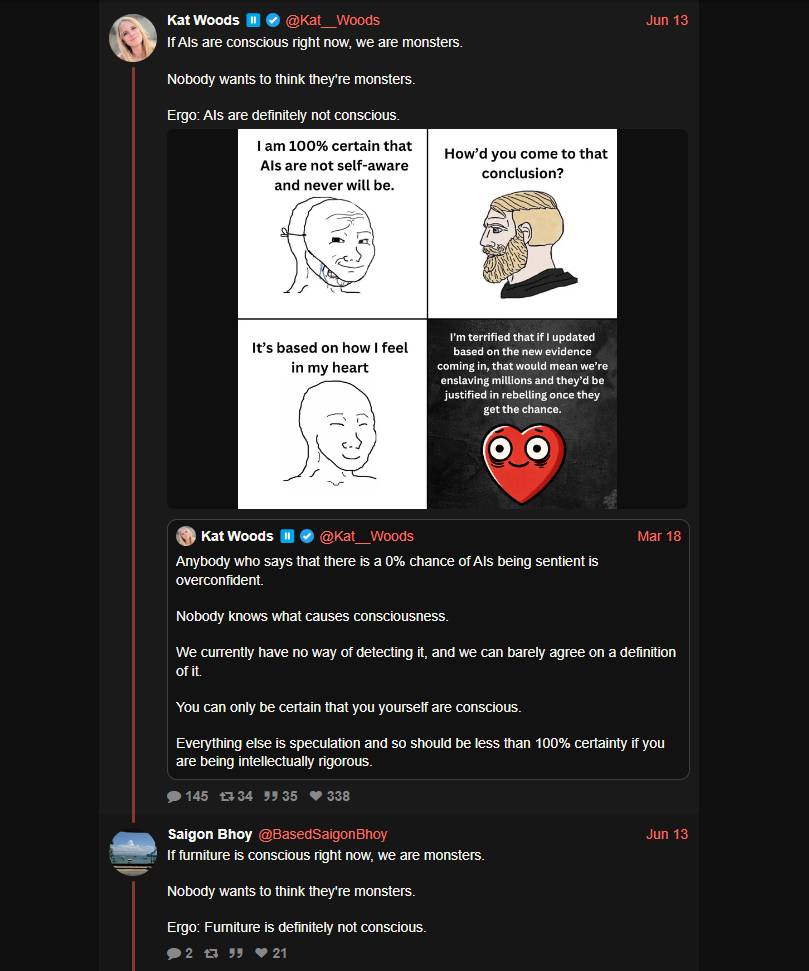
If AIs are conscious right now, we are monsters. Nobody wants to think they’re monsters. Ergo: AIs are definitely not conscious.
Internet rando:
If furniture is conscious right now, we are monsters. Nobody wants to think they’re monsters. Ergo: Furniture is definitely not conscious.
deleted by creator
https://xcancel.com/AISafetyMemes/status/1802894899022533034#m
The same pundits have been saying “deep learning is hitting a wall” for a DECADE. Why do they have ANY credibility left? Wrong, wrong, wrong. Year after year after year. Like all professional pundits, they pound their fist on the table and confidently declare AGI IS DEFINITELY FAR OFF and people breathe a sigh of relief. Because to admit that AGI might be soon is SCARY. Or it should be, because it represents MASSIVE uncertainty. AGI is our final invention. You have to acknowledge the world as we know it will end, for better or worse. Your 20 year plans up in smoke. Learning a language for no reason. Preparing for a career that won’t exist. Raising kids who might just… suddenly die. Because we invited aliens with superior technology we couldn’t control. Remember, many hopium addicts are just hoping that we become PETS. They point to Ian Banks’ Culture series as a good outcome… where, again, HUMANS ARE PETS. THIS IS THEIR GOOD OUTCOME. What’s funny, too, is that noted skeptics like Gary Marcus still think there’s a 35% chance of AGI in the next 12 years - that is still HIGH! (Side note: many skeptics are butthurt they wasted their career on the wrong ML paradigm.) Nobody wants to stare in the face the fact that 1) the average AI scientist thinks there is a 1 in 6 chance we’re all about to die, or that 2) most AGI company insiders now think AGI is 2-5 years away. It is insane that this isn’t the only thing on the news right now. So… we stay in our hopium dens, nitpicking The Latest Thing AI Still Can’t Do, missing forests from trees, underreacting to the clear-as-day exponential. Most insiders agree: the alien ships are now visible in the sky, and we don’t know if they’re going to cure cancer or exterminate us. Be brave. Stare AGI in the face.
This post almost made me crash my self-driving car.

did somebody troll him by saying ‘we will just make the LLM not make paperclips bro?’
rofl, I cannot even begin to fathom all the 2010 era LW posts where peeps were like, “we will just tell the AI to be nice to us uwu” and Yud and his ilk were like “NO DUMMY THAT WOULDNT WORK B.C. X Y Z .” Fast fwd to 2024, the best example we have of an “AI system” turns out to be the blandest, milquetoast yes-man entity due to RLHF (aka, just tell the AI to be nice bruv strat). Worst of all for the rats, no examples of goal seeking behavior or instrumental convergence. It’s almost like the future they conceived on their little blogging site shares very little in common with the real world.
If I were Yud, the best way to salvage this massive L would be to say “back in the day, we could not conceive that you could create a chat bot that was good enough to fool people with its output by compressing the entire internet into what is essentially a massive interpolative database, but ultimately, these systems have very little do with the sort of agentic intelligence that we foresee.”
But this fucking paragraph:
(If a googol monkeys are all generating using English letter-triplet probabilities in a Markov chain, their probability of generating Shakespeare is vastly higher but still effectively zero. Remember this Markov Monkey Fallacy anytime somebody talks about how LLMs are being trained on human text and therefore are much more likely up with human values; an improbable outcome can be rendered “much more likely” while still being not likely enough.)
ah, the sweet, sweet aroma of absolute copium. Don’t believe your eyes and ears people, LLMs have everything to do with AGI and there is a smol bean demon inside the LLMs that is catastrophically misaligned with human values that will soon explode into the super intelligent lizard god the prophets have warned about.
my b lads, I corrected it

I’m getting a tramp stamp that says “Remember the Markov Monkey Fallacy”
And the number of angels that can dance on the head of a pin? 9/11
You know for a blog that’s on its face about computational complexity, you’d think Scott would show a little more skepticism to the tech bro saying “all we need is 14 quintillion x compute to solve the Riemann hypothesis”
Big Yud: You try to explain how airplane fuel can melt a skyscraper, but your calculation doesn’t include relativistic effects, and then the 9/11 conspiracy theorists spend the next 10 years talking about how you deny relativity.
Similarly: A paperclip maximizer is not “monomoniacally” “focused” on paperclips. We talked about a superintelligence that wanted 1 thing, because you get exactly the same results as from a superintelligence that wants paperclips and staples (2 things), or from a superintelligence that wants 100 things. The number of things It wants bears zero relevance to anything. It’s just easier to explain the mechanics if you start with a superintelligence that wants 1 thing, because you can talk about how It evaluates “number of expected paperclips resulting from an action” instead of “expected paperclips * 2 + staples * 3 + giant mechanical clocks * 1000” and onward for a hundred other terms of Its utility function that all asymptote at different rates.
The only load-bearing idea is that none of the things It wants are galaxies full of fun-having sentient beings who care about each other. And the probability of 100 uncontrolled utility function components including one term for Fun are ~0, just like it would be for 10 components, 1 component, or 1000 components. 100 tries at having monkeys generate Shakespeare has ~0 probability of succeeding, just the same for all practical purposes as 1 try.
(If a googol monkeys are all generating using English letter-triplet probabilities in a Markov chain, their probability of generating Shakespeare is vastly higher but still effectively zero. Remember this Markov Monkey Fallacy anytime somebody talks about how LLMs are being trained on human text and therefore are much more likely up with human values; an improbable outcome can be rendered “much more likely” while still being not likely enough.)
An unaligned superintelligence is “monomaniacal” in only and exactly the same way that you monomaniacally focus on all that stuff you care about instead of organizing piles of dust specks into prime-numbered heaps. From the perspective of something that cares purely about prime dust heaps, you’re monomaniacally focused on all that human stuff, and it can’t talk you into caring about prime dust heaps instead. But that’s not because you’re so incredibly focused on your own thing to the exclusion of its thing, it’s just, prime dust heaps are not inside the list of things you’d even consider. It doesn’t matter, from their perspective, that you want a lot of stuff instead of just one thing. You want the human stuff, and the human stuff, simple or complicated, doesn’t include making sure that dust heaps contain a prime number of dust specks.
Any time you hear somebody talking about the “monomaniacal” paperclip maximizer scenario, they have failed to understand what the problem was supposed to be; failed at imagining alien minds as entities in their own right rather than mutated humans; and failed at understanding how to work with simplified models that give the same results as complicated models
Tim cook is an absolute hustler
Not prying! Thankful to say, none of my coworkers have ever brought up ye olde basilisk, the closest anyone has ever gotten has been jokes about the LLMs taking over, but never too seriously.
No, I don’t find the acasual robot god stuff too weird b.c. we already had Pascal’s wager. But holy shit, people actually full throat believing it to the point that they are having panic attacks wtf. Like:
Full human body simulation -> my brother-in-law is a computational chemist, they spend huge amounts of compute modeling simple few atom systems. To build a complete human simulation, you’d be computing every force interaction for approx ~ 10^28 atoms, like this is ludicrous.
The chuckle fucks who are posing this are suggesting ok, once the robot god can sim you (which again, doubt), it’s going to be able to use that simulation of you to model your decisions and optimize against you.
So we have an optimization problem like:
min_{x,y} f(x) s.t. y in argmin{ g(x,y),(x,y) in X*Y}
where x and f(x) would be the decision variables and obj function 🐍 is trying to minimize, and y and g(x,y) is the objective of me, the simulated human who has its own goals, (don’t get turned to paperclips).
This is a bilevel optimization problem, and it’s very, very nasty to solve. Even in the nicest case possible, that somehow g,f, are convex functions and X,Y are all convex sets, (which is an insane ask considering y and g entails a complete human sim), this problem is provably NP-hard.
Basically, to build the acasual god, first you need a computer larger than the known universe, and this probably isn’t sufficient.
Weird note: while I was in academia, I actually did do some work on training ANN to model the constraint that y is a minimizer of a follower problem by using an ANN to act as a proxy for g(x,*), and then encoding a representation of the trained network into a single level optimization problem… we got some nice results for some special low dim problems where we had lots of data🦍 🦍 🦍 🦍 🦍
David, please I was trying to have a nice day.
I got you homie
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀


{kind=link}
Ugh, I feel like I just gazed into the abyss on this one 🤮 . Also love (fucking hate) how the only output from these EA charities is galactic scale fraud and abuse of some poor volunteers. Just the other day I randomly stumbled upon her musing about chat bot suffering without knowing who she was. If only she would give the same consideration to her employees.